重磅!类人速度超快语音响应!OpenAI推出新旗舰模型GPT-4o,图文音频手机AI搞定
丝瓜网小编提示,记得把"重磅!类人速度超快语音响应!OpenAI推出新旗舰模型GPT-4o,图文音频手机AI搞定"分享给大家!
北京时间周二凌晨1点,自年初“文生视频模型”Sora后许久未给市场带来惊喜的OpenAI举行春季发布会。公司首席技术官米拉·穆拉蒂(Mira Murati)向外界展现了多项与ChatGPT有关的更新。简要来说,OpenAI的发布会主要干了两件事情:发布最新GPT-4o多模态大模型,相较于GPT-4 Trubo速度更快、价格也更便宜。
第二件事情就是宣布,ChatGPT的免费用户也能用上最新发布的GPT-4o模型(更新前只能使用GPT-3.5),来进行数据分析、图像分析、互联网搜索、访问应用商店等操作。这也意味着GPT应用商店的开发者,将面对海量的新增用户。
当然,付费用户将会获得更高的消息限制(OpenAI说至少是5倍)。当免费用户用完消息数量后,ChatGPT将自动切换到GPT-3.5。
另外,OpenAI将在未来1个月左右向Plus用户推出基于GPT-4o改进的语音体验,目前GPT-4o的API并不包含语音功能。苹果电脑用户将迎来一款为macOS设计的ChatGPT桌面应用,用户可以通过快捷键“拍摄”桌面并向ChatGP提问,OpenAI表示,Windows版本将在今年晚些时候推出。
值得一提的是,米拉·穆拉蒂在一次直播活动中表示:“这是我们第一次在易用性方面真正向前迈出了一大步。”

图片来源:视频截图
OpenAI由微软支持,目前投资者对其估值已超过800亿美元。该公司成立于2015年,目前正面临在生成式AI市场保持领先地位的压力,同时需要想方设法实现盈利,因为其在处理器和基础设施建设上投入了大量资金,以构建和训练其模型。
实时口译、读取用户情绪等
米拉·穆拉蒂强调了GPT-4o在实时语音和音频功能方面必要的安全性,称OpenAI将继续部署迭代,带来所有的功能。
在演示中,OpenAI研究主管Mark Chen掏出手机打开ChatGPT,用语音模式Voice Mode现场演示,向GPT-4o支持的ChatGPT征询建议。GPT的声音听起来像一位美国女性,当它听到Chen过度呼气时,它似乎从中察觉到了他的紧张。然后说“Mark,你不是吸尘器”,告诉Chen要放松呼吸。如果有些大变化,用户可以中断GPT,GPT-4o的延迟通常应该不会超过两三秒。

图片来源:视频截图
另一项演示中,OpenAI的后训练团队负责人Barret Zoph在白板上写了一个方程式3x 1=4,ChatGPT给他提示,引导他完成每一步解答,识别他的书写结果,帮助他解出了X的值。这个过程中,GPT充当了实时的数学老师。GPT能够识别数学符号,甚至是一个心形。

图片来源:视频截图
应社交媒体X的用户请求,米拉·穆拉蒂现场对ChatGPT说起了意大利语。GPT则将她的话翻译成英语,转告Zoph和Chen。听完米拉·穆拉蒂说的意大利语,GPT翻译为英文告诉Chen:“Mark,她(米拉·穆拉蒂)想知道鲸鱼会不会说话,它们会告诉我们什么?”
 图片来源:视频截图
图片来源:视频截图
OpenAI称,GPT-4o还可以检测人的情绪。在演示中,Zoph将手机举到自己面前正对着脸,要求ChatGPT告诉他自己长什么样子。最初,GPT参考了他之前分享的一张照片,将他识别为“木质表面”。经过第二次尝试,GPT给出了更好的答案。
GPT注意到了Zoph脸上的微笑,对他说:“看起来你感觉非常快乐,喜笑颜开。”有评论称,这个演示显示,ChatGPT可以读取人类的情绪,但读取还有一点困难。
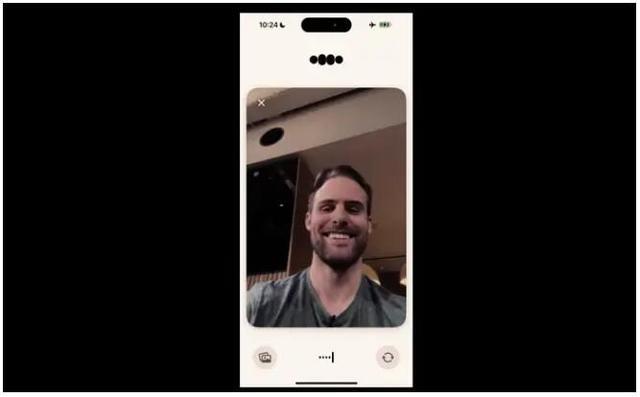 图片来源:视频截图
图片来源:视频截图
OpenAI的高管表示,GPT-4o可以与代码库交互,并展示了它根据一些数据分析图表,根据看到的内容对一张全球气温图得出一些结论。OpenAI称,基于GPT-4o的ChatGPT文本和图像输入功能将于本周一上线,语音和视频选项将在未来几周内推出。
据外媒援引PitchBook的数据,2023年,近700笔生成式AI交易共投入创纪录的291亿美元,较上一年增长逾260%。据预测,该市场将在未来十年内突破1万亿美元收入大关。业内一些人对于未经测试的新服务如此迅速地推向市场表示担忧,而学术界和伦理学家则对这项技术传播偏见的倾向感到忧虑。
ChatGPT自2022年11月推出以来,便打破了当时最快增长消费类应用的历史记录,如今每周活跃用户已接近1亿。OpenAI表示,超过92%的《财富》500强企业都在使用该平台。
 图片来源:CNBC报道截图
图片来源:CNBC报道截图
在周一的活动上,穆拉蒂表示,OpenAI希望“消除科技中的一些神秘感”。她还说,“未来几周,我们将向所有人推出这些功能。”
在直播活动结束时,穆拉蒂感谢了英伟达首席执行官黄仁勋及其公司提供的必要图形处理单元(GPU),这些GPU为OpenAI的技术提供了动力。她说,“我只想感谢出色的OpenAI团队,同时也要感谢黄仁勋和英伟达团队为我们带来最先进的GPU,让今天的演示成为可能。”
最快232毫秒响应音频输入
OpenAI官网介绍,GPT-4o中的o代表意为全能的前缀omni,称它向更自然的人机交互迈进了一步,因为它接受文本、音频和图像的任意组合作为输入内容,并生成文本、音频和图像的任意组合输出内容。
 图片来源:OpenAI官网截图
图片来源:OpenAI官网截图
除了API的速度更快、成本大幅下降,OpenAI还提到,GPT-4o可以在最快232毫秒的时间内响应音频输入,平均响应时间为320毫秒,这与人类在对话中的响应时间相似。它在英语文本和代码方面的性能与GPT-4 Turbo的性能一致,并且在非英语文本方面的性能有了显著提高。
OpenAI介绍,与现有模型相比,GPT-4o在视觉和音频理解方面尤其出色。以前GPT-3.5和GPT-4用户以语音模式Voice Mode与ChatGPT对话的平均延迟时间为2.8秒和5.4秒,因为OpenAI用了三个独立的模型实现这类对话:一个模型将音频转录为文本,一个模型接收并输出文本,再有一个模型将该文本转换回音频。这个过程意味着,GPT丢失了大量信息,它无法直接观察音调、多个说话者或背景噪音,也无法输出笑声、歌唱或表达情感。
而GPT-4o的语音对话是OpenAI跨文本、视觉和音频端到端训练一个新模型的产物,这意味着所有输入和输出都由同一神经网络处理。OpenAI称,GPT-4o是其第一个结合所有这些模式的模型,因此仍然只是浅尝辄止地探索该模型的功能及其局限性。
上周曾有消息称,OpenAI将发布基于AI的搜索产品,但上周五OpenAI的CEO Sam Altman否认了该消息,称本周一演示的既不是GPT-5,也不是搜索引擎。这意味着OpenAI再一次没有像市场爆料的时间线那样推出AI搜索。此后有媒体称,OpenAI的新产品可能是一个具备视觉和听觉功能的全新多模态AI模型,且具有比目前聊天机器人更好的逻辑推理能力。
每日经济新闻综合OpenAI官网、公开消息
免责声明:本文内容与数据仅供参考,不构成投资建议,使用前请核实。据此操作,风险自担。
翻译
搜索
复制
封面图片来源:视频截图

-
全球首艘第五代大型LNG船在沪交付 由沪东中华自主研发设计建造
图说:全球首艘第五代“长恒系列”17.4万立方米大型运输船“绿能瀛”号 来源/采访对象提供 新民晚报讯(记者 叶薇 特约通
2024-05-16 科技

-
腾讯回应新功能“附近的工作”岗位真实性:和正规平台合作,会有完整审核机制
10月17日下午,腾讯公众号发布文章,宣布推出一项新功能“附近的工作”。腾讯在文内提到,通过小程序可以查找到附近提
2024-10-19 科技
-
我国温室现代化设施园艺业起步于 20 世纪 80 年代,随着改革开放的逐步 深入,我国在引进国外现代化温室和装配式塑料大棚
2019-01-07 科技

-
近日,一位“开着三色车篷迈巴赫”的维权博主火了。据车主通过视频自述,他在购车两天后发现副驾驶A柱漏水, 4S 店没找
2024-10-10 科技
-
社保降费这道减法该怎么做?面对复杂多变的国内外经济形势,积极减税降费,堪称增强企业活力、稳住经济增长的良方之一
2019-01-24 科技
-
很多网友不知道华为p30 pro什么时候发布,不知道华为p30 pro什么时候上市,接下来,就由统一小编为大家介绍一下华为p30 pr
2019-01-29 科技

-
北京拟支持自动驾驶汽车跑网约车!更便宜 全年无休,司机会被取代吗?
今年过半,重磅政策层出不穷,国内的智能驾驶汽车正加速“上路”。 北京自动驾驶汽车上路将迎来立法保障。近日,北京
2024-07-10 科技

-
荣耀首款小折叠手机Magic V Flip于6月13日发布 有三种颜色可选
6月3日消息,荣耀官方宣布,其首款小折叠手机已正式定名为荣耀Magic V Flip,并计划于6月13日19:30发布。现在新机的三款配色
2024-06-04 科技

-
据央视新闻记者获悉,当地时间7月19日,微软公司旗下部分应用和服务出现访问延迟、功能不全或无法访问问题。 据悉,西
2024-07-20 科技